Symphony makes it easy for developers to build
real-time
collaborative applications
Simple to Manage and Deploy
Cloud Native and Ready to Scale
"Alone we can do so little; together we can do so much." - Hellen Keller
Collaboration has been a key feature of the internet since its earliest days. The history of collaboration on the internet can be traced back to the 1960s, when Douglas Engelbart, the inventor of the computer mouse, studied how computers could support collaborative work and communication. He developed a system called NLS (oN-Line System) that allowed users to create and edit documents, link them together, and share them with others.
Of course, for much of the internet’s history, collaboration had to be done by taking turns – collaborators might email a document back and forth after each round of changes, for example.
Even today, many online editing tools do not allow for concurrent changes by multiple users in real-time. Basecamp, for example, is an online collaboration platform that allows users to share and work on the same documents. What happens, though, when more than one user wants to edit a document at the same time?
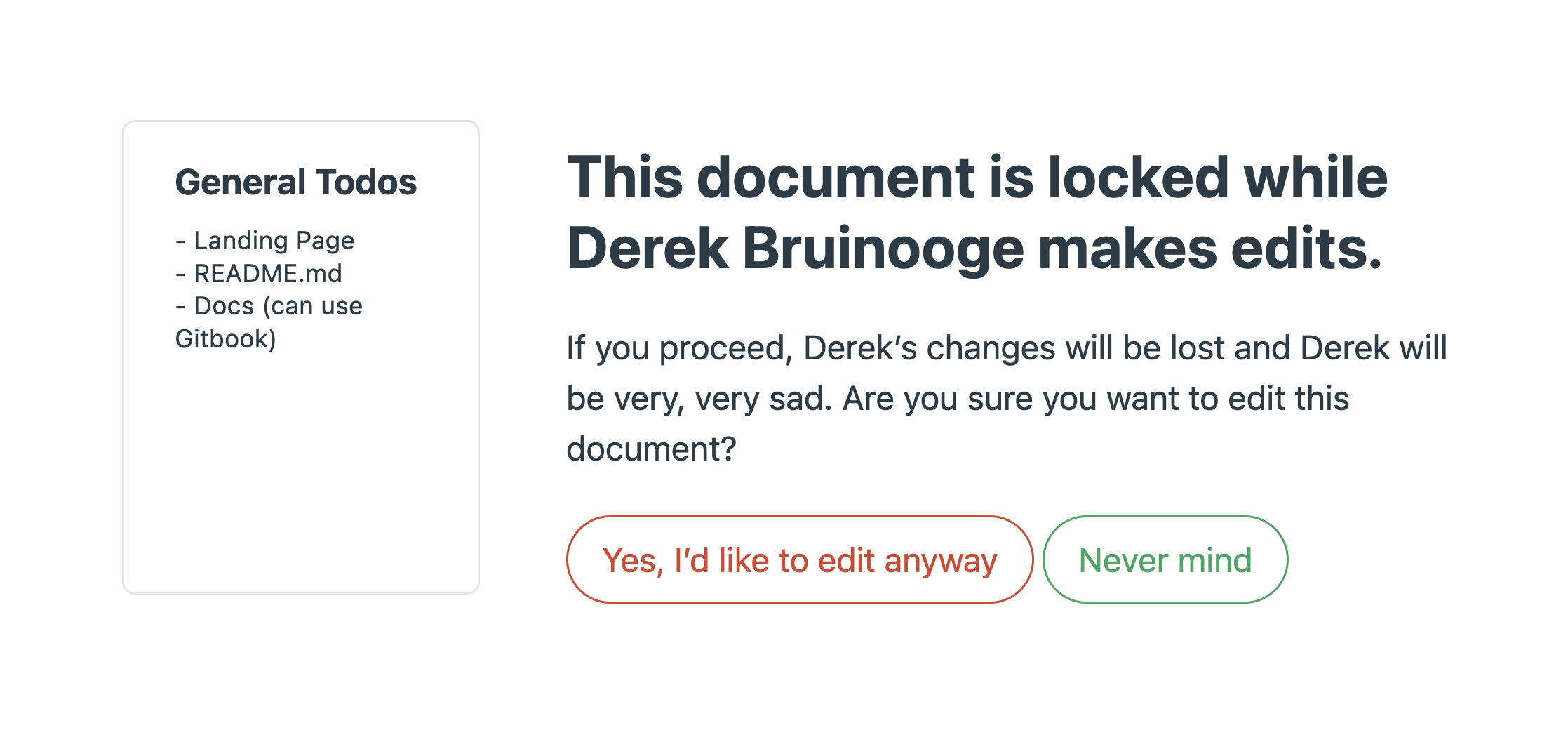
As the above image shows, online collaboration via Basecamp is not real-time–only one user is allowed to modify content at a time, and others must wait for that user to finish before making their own changes.

Contrast that with applications such as Figma, Google Docs, Miro, and Trello that allow users to modify shared content at the same time - in other words, collaborate in real-time.
Real-time collaboration refers to the ability for multiple users to work on the same document or project simultaneously and see the changes made by others as they happen. Real-time collaboration has become so prevalent that some deem it an essential aspect of many modern web applications, one that has opened up new ways of working together on the web.
"[Real-time collaboration] eliminates the need to export, sync, or email copies of files and allows more people to take part in the design process." - Evan Wallace, Figma
Symphony is a framework for providing real-time collaboration functionality to web applications.
What does that mean?
Let’s illustrate this with a simple whiteboard application that we’ve created for demo purposes. Users can perform the basic actions you’d expect in this kind of app, like drawing lines, adding shapes, changing colors, and so on. At this point, this is just a single-user application that does not support multi-user collaboration.
Go ahead, give it a try.
Now let’s add Symphony into the mix. By deploying the Symphony backend to AWS and connecting it with our whiteboard, the application is now collaborative. Users can work together in the same collaborative space and see what others are doing in real-time.
Try and see what happens when you draw on either of the below whiteboards.
In this case study, we will explore the components of web-based real-time collaboration, review existing solutions that can enable real-time collaboration in applications, and present our project, Symphony: how developers can use it, how we created it, and the trade-offs we weighed during the development process.
First, let’s explore what we mean by “real-time collaboration.”
For an application to feature real-time collaboration, the first requirement is that data must be exchanged between users, or between users and a server, in real-time. Generally, that means that a user sees updated data either instantly or without noticeable delay, and without needing to take any specific action or make any particular request to see the updated data.
For the purposes of real-time collaboration, data must flow in two directions: from the user, when that user makes a change that will be shared with others, and to the user, when someone else makes a change.
When building a real-time web application, challenges arise because HTTP, the protocol by which most web communication occurs, is not real-time by design. Instead, HTTP uses a request-response model whereby the client sends a request to a server and then waits for the server to respond with the requested data.
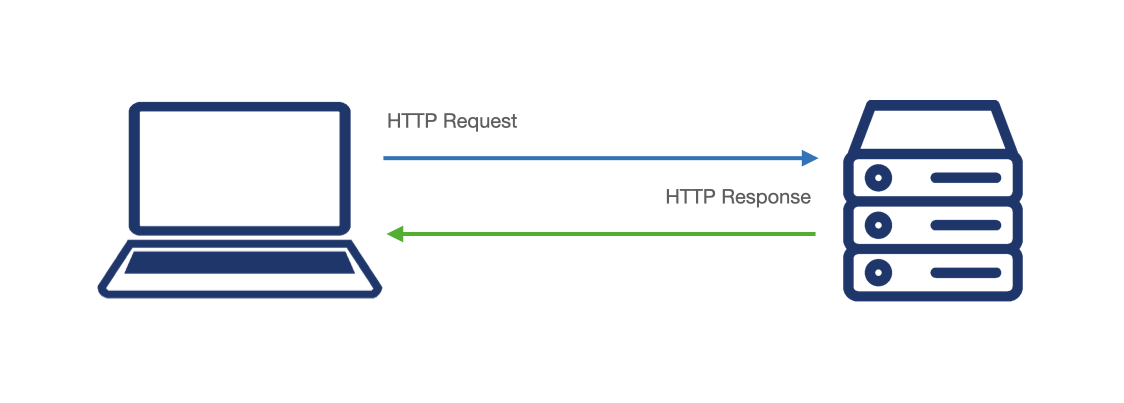
So how can we make an application that lets users see a constant stream of updated data? For bi-directional, real-time data exchange over the web, two protocols in particular merit our consideration: WebRTC and WebSocket.
WebRTC, which stands for Web Real-Time Communication, is an open-source project that allows web browsers and mobile applications to engage in peer-to-peer real-time communication via APIs. The connection between peers is established with the use of a signaling server that acts as an initial intermediary, allowing two clients to find each other and negotiate connection parameters. Once the connection is established, data is transferred directly between the peers via media streams and/or data channels.
Since WebRTC is primarily used over UDP, it offers superior latency at the cost of some packet loss. This makes it an especially attractive choice for video and audio streaming.
WebSocket is a protocol that provides a two-way channel of real-time communication between a client and a server. The connection is established via the WebSocket handshake:
Upgrade header
Connection: Upgrade and Upgrade: Websocket headers
Once the handshake is complete, the WebSocket connection is established using the same underlying TCP/IP connection used in the handshake. Either party is now free to send data at any time via this connection.
WebSocket provides better data integrity than WebRTC due to the underlying reliability of TCP, which provides error detection, acknowledgement, and flow/congestion control mechanisms to ensure the accurate, complete, and in-order delivery of data. WebSocket is therefore often used in situations where delivering accurate data is paramount (e.g. real-time dashboards, stock price tickers) and where minimizing latency is less critical (e.g. live text chat).
As we have seen, both WebRTC and WebSocket have trade-offs that make each better for some use cases and less suitable for others. When designing Symphony, we thought about which of these two technologies would be better for our use case.
Applications that would use Symphony are likely already using the client-server model, which lies at the heart of modern web applications. As a protocol based on a client-server model, WebSocket was therefore a natural choice for us.
Now that we’ve established what “real-time” means and how it can be achieved over the web, let’s turn to collaboration. What do we mean by “collaboration,” and what are some of its components?
First, let’s consider a simple chat application. Imagine we have two users, Alice and Bob, exchanging messages in real-time. As soon as one user enters a message, the other user sees the message displayed without noticeable delay. Is this an example of a collaborative application?
The answer is no. While the two users are exchanging information in real-time, they are not collaborating because they are not modifying the same state. Each user has control only over his or her own messages, and each of these messages is independent of the others. Alice can see Bob’s messages in real-time, but she cannot modify them.
Now let’s look at a different kind of application.
This time, Alice and Bob are using an online word processor to work together on a document. Alice and Bob are each making their own changes, but they are viewing the same document, reflecting the modifications made by both users to that document, in real-time. Therefore we can say that there exists a shared state between Alice and Bob.
This shared state, which is reflected in a single synchronized view presented to all users working on the same document or project, lies at the core of real-time collaborative applications.
Let’s now review some concepts that are critical to understanding how online collaboration works.
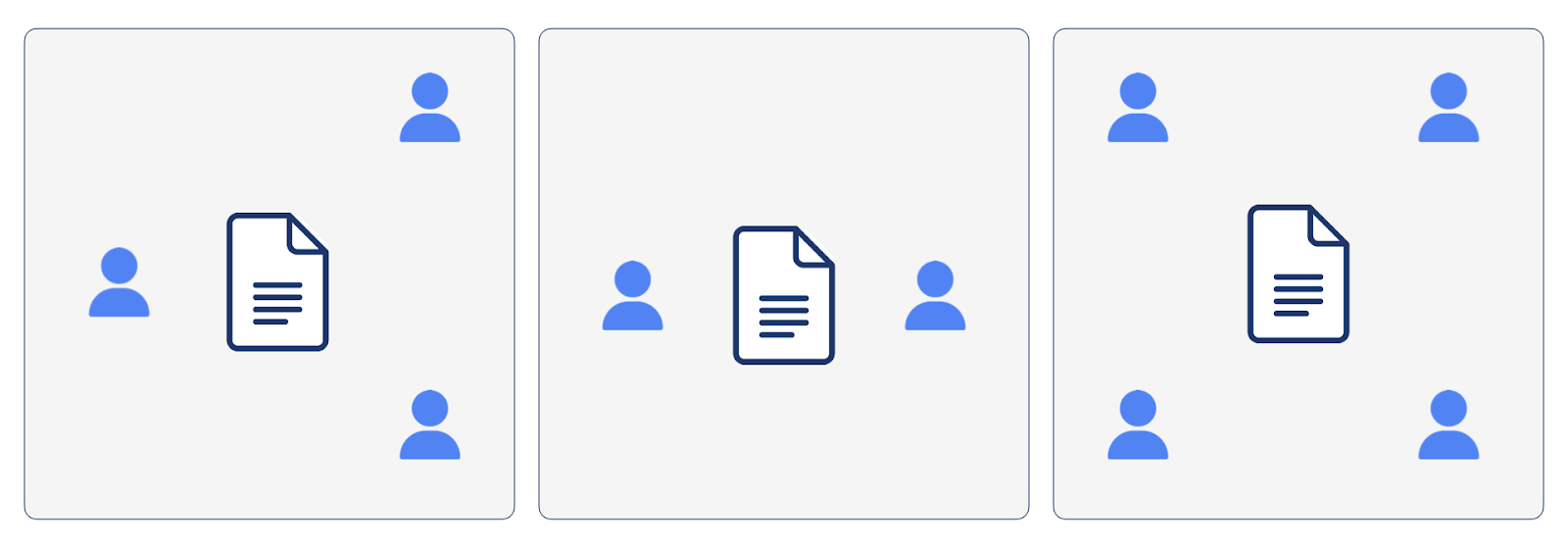
Collaboration is something that happens when two or more users work together on a specific document or project. We call this group of collaborating users, together with the shared state they are collaborating on, a room. This is consistent with the nomenclature favored by others in this space including Liveblocks, a provider of real-time collaboration as a service:
"A room is the space people can join to collaborate together."" - Liveblocks
A document is the shared state that users are collaborating on. Keep in mind that collaboration is not limited to text documents; a document could also be a JavaScript Map with key/value pairs that represent drawn objects on a whiteboard, for example.
When collaborating with others, it is useful to see not only the current state of the document but also which users are currently present and what they are doing at any given moment. Seeing what other users are doing in real-time makes for a smoother and more meaningful collaborative experience.
We call this feature presence, which is the term most commonly used by other providers of real-time collaboration tools, including Liveblocks. In Symphony, each client sends an update to the server when some aspect of presence–cursor position for example– has changed. Which data to include in these presence updates, and the way that data is structured, is left to the application developer.
It should be noted that presence data is distinct from the shared state (document) that is the subject of users’ collaboration. Importantly, presence data is ephemeral and does not need to be persisted in the backend.
Another concept worth discussing when it comes to collaborative applications is the ability of users to undo (and/or redo) their updates.
When only a single user is editing, the concept of undo is simple: simply revert to the state immediately preceding the most recent change.
However, when multiple users are making changes, the picture gets more complicated. If a user’s undo action simply returns the state to that immediately preceding that user’s last update, what happens to intervening updates by others?
When Bob clicks the undo button, Alice’s red triangle is deleted. That’s probably not what either person wanted!
So going back to the state preceding the user’s change is not the answer. What we want instead is to make the undo/redo behavior user-specific, with the scope of these actions limited to the user’s own changes.
When Bob clicks “Undo”, his color change to the circle is reverted, but Alice’s red triangle remains in place.
Turning back to Alice and Bob’s document, let’s imagine that Alice and Bob make different changes to the same content at the same time. What might happen then?
Here, Alice and Bob have different ideas for what a good title would be, and they each transmit a change to the title at the same time. Next, Bob’s change is delivered to Alice, which overrides the state presented in her client–she now sees Bob’s version. Meanwhile, Alice’s change is delivered to Bob, which overrides his local state, and he is now shown Alice’s version. This means that Alice and Bob are out of sync, and we’ve lost the critical underpinning of real-time collaboration - a shared state.
Another source of conflict in collaborative applications is out-of-order delivery of messages.
In a non-collaborative application like a chat program, this is generally not a critical problem.
Turning back to Alice and Bob’s document, though, what happens if Alice makes some changes, but due to network conditions these updates are delivered to Bob out of order?
Here, Alice makes two changes to the title, but due to network conditions the changes are delivered to Bob in reverse order. Bob’s state now reflects the first change, while Alice’s state reflects the second. Again, the users find themselves out of sync.
It’s acceptable - even inevitable - for users to go out of sync temporarily, but we need some way of ensuring that they will eventually converge again to the same state. In the end, we want all users to see the same document on their screen, reflecting all the changes that have been made.
So how can we deal with this problem? There are generally two families of algorithms that are used to resolve conflicts in collaborative applications.
Operational transformation (OT) is the traditional technique to synchronize and reconcile concurrent changes to a shared data structure in real-time collaborative applications. When a user inserts or deletes data, that change is first sent to the server. The server then modifies, or transforms, that change if necessary, before sending it on to other users.
Used most famously by Google Docs, OTs are especially good for text editing of long documents with low memory and performance overhead. They do have downsides, however. They generally require that a user be connected to the server at all times, limiting the user’s ability to work offline and sync up later after connecting. Most importantly, they are very hard to implement correctly. It is difficult to deal with all edge cases, and many papers on OT implementations were found to have errors, years after publication.
"Unfortunately, implementing OT sucks. There's a million algorithms with different tradeoffs, mostly trapped in academic papers. The algorithms are really hard and time consuming to implement correctly." - Joseph Gentle, former Google Wave engineer
A Conflict-Free Replicated Data Type (CRDT) is a type of data structure that is designed to be replicated across multiple devices. CRDTs have mathematical properties that guarantee eventual consistency, even in the presence of concurrent, conflicting updates.
A relatively new concept aiming to solve problems in distributed computing, CRDTs have become a popular choice in resolving merge conflicts arising out of real-time collaboration, which can be seen as a kind of distributed system where state is shared across multiple clients.
Unlike OT, CRDTs do not make any assumptions about your network topology–they can be used in a strictly peer-to-peer environment, but also work perfectly well in a client-server model.
"Even if you have a client-server setup, CRDTs are still worth researching because they provide a well-studied, solid foundation to start with."" - Evan Wallace, Figma
Another key characteristic of CRDTs not shared by OT is partition fault tolerance. In a distributed system, network partitions can occur due to congestion or hardware failures. With CRDTs, even if two disconnected users update the same content concurrently, the updates will eventually merge when the partition is resolved.
Early CRDTs were found to be relatively slow compared to their OT counterparts. Another potential downside is memory overhead, since every change to a document creates more data that must be retained to guarantee consistency.
"Because of how CRDTs work, documents grow without bound. … Can you ever delete that data? Probably not. And that data can’t just sit on disk. It needs to be loaded into memory to handle edits." - Joseph Gentle, former Google Wave engineer
Recent work by Martin Kleppmann and others has made CRDTs faster and less memory hungry. These advancements have led CRDTs to overtake OT as the tool of choice for real-time collaboration in the estimation of some researchers.
So which choice is best?
The first thing to point out is that there is no single best, one-size-fits-all solution to resolving merge conflicts. The best choice will, therefore, depend on the specific use case.
For Symphony, we were looking for something that was open-source, well-documented, and performant. We also wanted a solution that would allow users to work offline. These factors led us to select CRDTs due to their robust open-source implementations, recent performance improvements, and tolerance for network partitions.
For the specific CRDT implementation we chose Yjs, a mature library with an active community and tools ecosystem. Yjs has also been battle-tested in production applications including:
We also considered using Automerge, the other leading open-source offering in this space. There was probably not a wrong choice to be made between the two, but we were ultimately persuaded by Yjs’s superior maturity and speed, as well as its relative memory efficiency.
Now that we understand the ingredients of real-time collaboration, let’s place ourselves in the shoes of a developer who wishes to add real-time collaboration to an application. What kinds of functionality and infrastructure will we need?
First, we’ll want a WebSocket server or servers to receive updates from users and transmit those updates to other users who are in the same room.
Next, we’ll need a means of resolving merge conflicts.
Ideally, we will also have a way of persisting room state. When users leave a room, they probably don’t want to lose all of their work. Instead, they should be able to return later and pick up where they left off. This can be achieved by storing room state in a database when users disconnect, and retrieving that state from the database when they reconnect.
What if a user loses their internet connection but wants to continue working on a document? Wouldn’t it be nice if a user’s offline changes can be stored and then synced back up with others when the user reconnects? To enable this, we’ll want a way for each client to store state locally.
Finally, from the developer’s perspective, it could be useful to know how users are collaborating in an application. A developer dashboard might be one way of gaining visibility into metrics like the number of rooms, the number of users per room, and the size of the document associated with a given room.
What then are the developer’s options for obtaining this functionality and related infrastructure?
One option is for the developer to implement or source each of these components separately and stitch them together.
For the backend infrastructure to handle real-time messaging and persist state, one could use a backend-as-a-service such as Ably, Pusher, or PubNub, or alternatively deploy one’s own backend by provisioning resources on a cloud provider like AWS.
For conflict resolution, the developer would most likely need to research and integrate an existing open-source solution. She might even choose to implement a bespoke conflict resolution implementation, although this would be considerably more time-consuming and difficult.
In sum, going the DIY route is less costly, but the implementation burden on the developer in terms of sourcing and integrating the needed components is higher than using one of the services described in the next section.
Building out your own backend to manage websocket connections and implementing or integrating a means of conflict resolution can be challenging. For this reason, services and frameworks exist to abstract away the backend and conflict resolution and let the developer focus on the application itself.
"Because building low-latency, collaborative experiences is hard!" - Microsoft
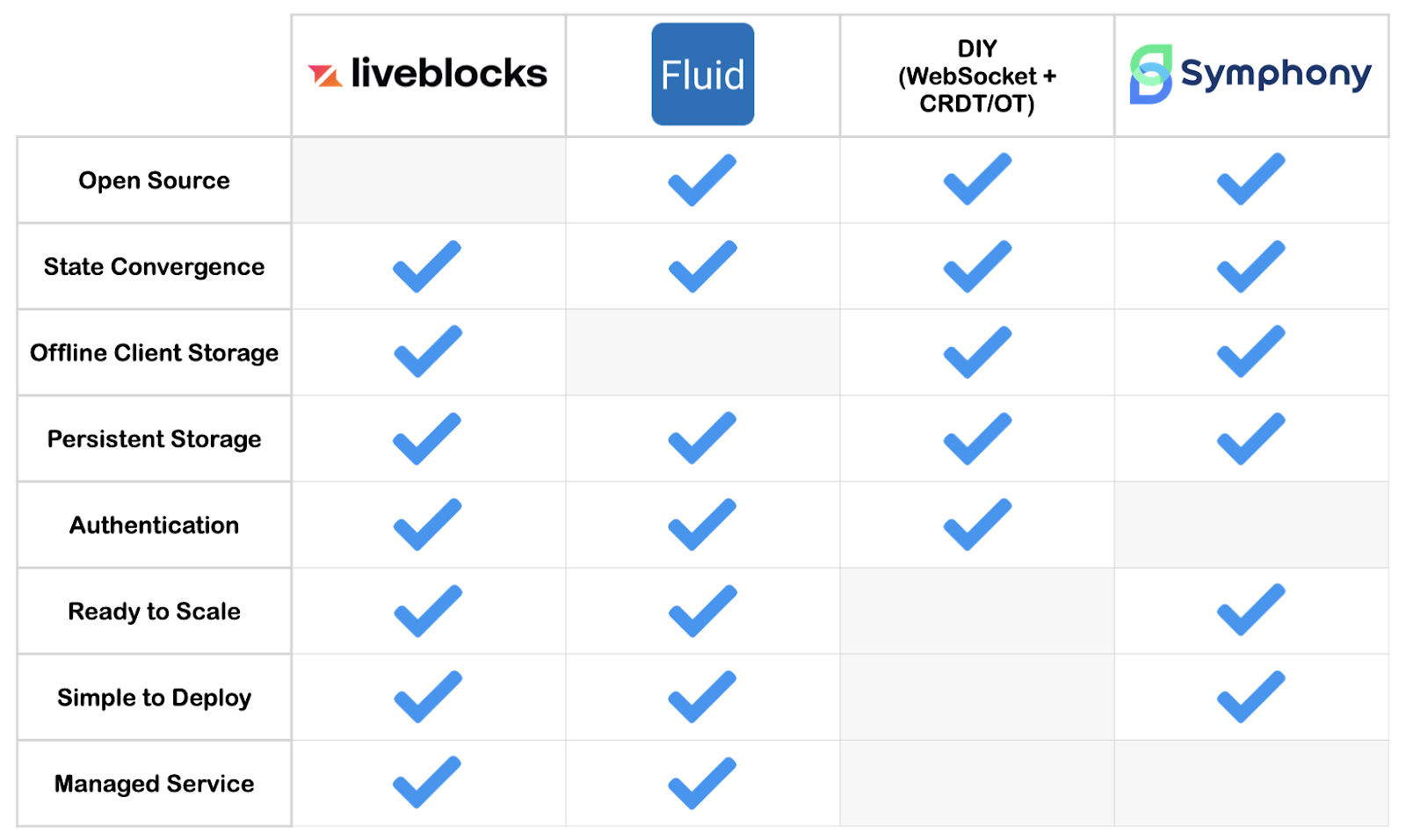
Liveblocks is a major player in this space that provides an all-in-one solution for developers wishing to add real-time collaboration to their applications. A service that takes care of managing and scaling the WebSocket infrastructure, Liveblocks also provides a custom CRDT-like solution for resolving merge conflicts. This convenience comes at a cost, however: for an application with up to 2,000 monthly active users, the price is $299 as of this writing.
Fluid Framework is an open-source, cloud-agnostic framework for real-time collaboration, developed by Microsoft. For conflict resolution, it uses a distributed data structure that Microsoft describes as “more similar to CRDT than OT” . When deployed on a single server, Fluid Framework can handle hundreds of concurrent users. For larger applications, however, the developer will need to implement her own scaling solution. Another drawback of Fluid Framework is that it does not include support for offline editing, although short periods of client disconnection are tolerated.
While Fluid Framework itself is open-source and self-hosted, Microsoft also offers a managed service called Azure Fluid Framework that uses Fluid Framework under the hood.
We drew inspiration from both Liveblocks and Fluid Framework. Our goal was to build a framework that developers can easily integrate into existing applications to add real-time collaborative functionality. We also wanted to make Symphony available to developers free of charge as an open-source project, and to enable offline editing functionality so that developers could achieve a better experience for their users.
Additionally, we decided to implement a dashboard to address a couple of potential problems developers might face after deployment.
First, given the memory requirements of CRDTs and the considerable CPU demands placed on the server as it receives and propagates updates, system limits could be exceeded if not actively monitored. The dashboard provides developers with visibility into metrics such as number of rooms, sizes of documents stored in rooms, and numbers of connections per room that will help identify when and why performance problems occur.
Second, the dashboard can be used to view the current state of a room in JSON format. This can serve as a debugging tool when the developer’s application is not storing and modifying state as expected.
In short, Symphony is aimed at developers of collaborative web applications who want to get real-time collaboration up and running quickly on a smaller budget.
When designing Symphony, our decisions were informed at every step of the way by the fundamental problem we aimed to address: that building collaborative applications where multiple users can change a given piece of state concurrently is difficult.
With this in mind, we aimed to provide the infrastructure needed for creating conflict-free collaborative experiences on the web in a way that is easy for developers to drop into their existing applications.
We wanted to abstract away the complexity of managing and scaling WebSocket connections, resolving merge conflicts, and persisting state so that developers would be free to focus on their applications.
Finally, we wanted the framework to provide capacity comparable to the highest level of Liveblocks’ Pro tier, which supports up to 25,000 monthly active users. Assuming 10%-30% of MAUs online at any given time, and choosing to err on the high side, we arrived at a goal of 8,000 concurrent active users.
Our first goal when building Symphony was to create a basic prototype of the system. We chose to do this in AWS, which was a natural choice as the biggest player in the cloud provider market with 32% market share as of early 2023.
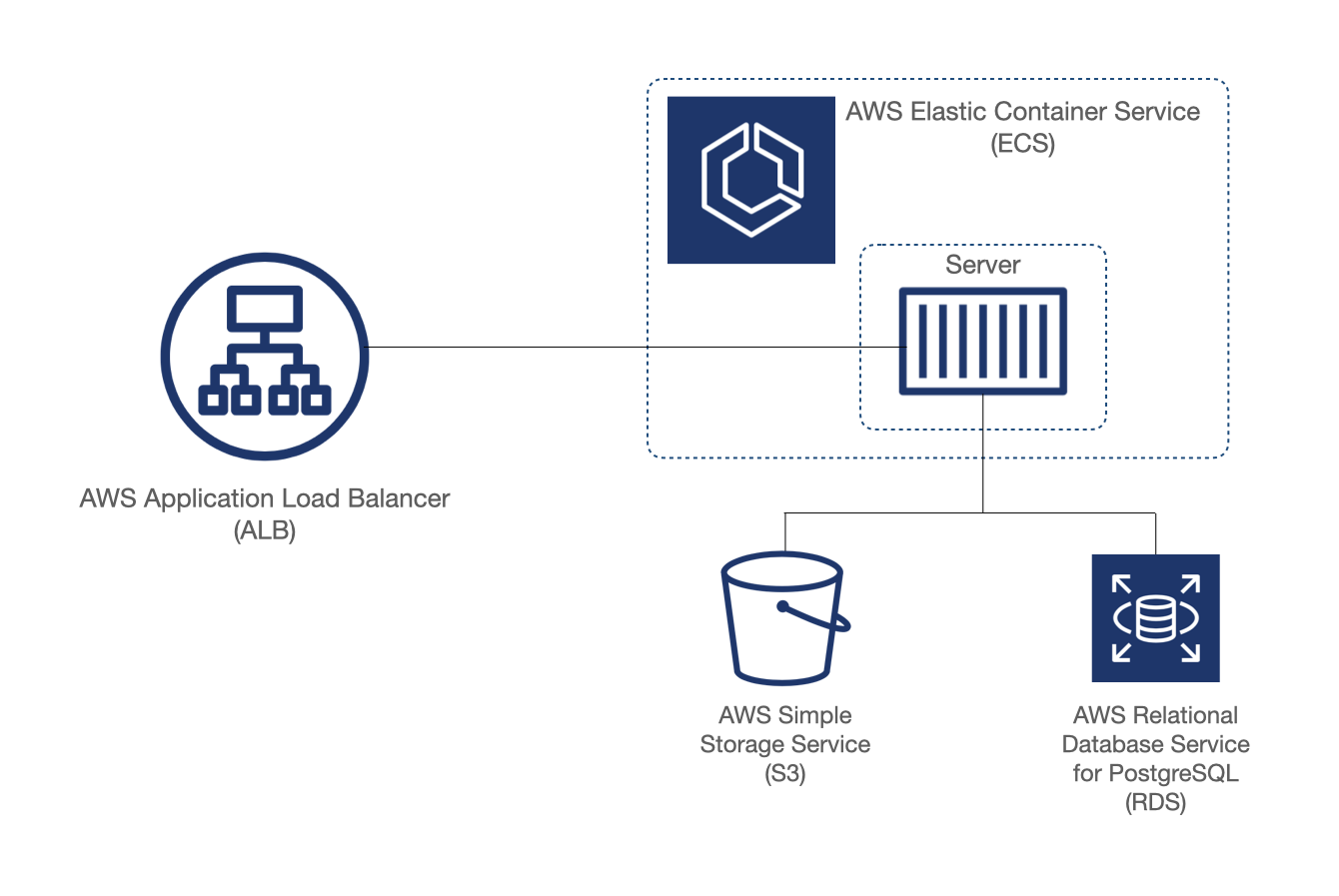
Since we are using the WebSocket protocol for real-time data transfer, we will need a WebSocket server to receive and distribute messages. And since we have chosen the Yjs CRDT implementation, our starting point for the Symphony backend was y-websocket, a reference WebSocket server that implements the Yjs protocols for syncing updates and broadcasting presence. We deployed the server to Amazon Elastic Compute Cloud (EC2), which is the standard virtual private server offered by AWS.
When a collaboration session ends, users will likely want to come back later and continue where they left off. When they reconnect, where will the previous state come from? One or more users might have it stored locally, but that local data could be lost if they cleared their browser cache.
Our next step was therefore to modify the server to persist document data to a database so that users would be able to leave a room without losing their work.
The main decision points here were 1) where to persist the data and 2) when to persist the data.
For the storage location, we chose Amazon Simple Storage Service (S3). S3 provides object storage, which is ideal for persisting large amounts of unstructured data such as our room documents. We also considered using a NoSQL database like Amazon DynamoDB, but found that S3 would be cheaper as the costs for storing a given amount of data are significantly lower in S3 compared to DynamoDB. S3 is also more practical for use cases like ours with unbounded document size, as the maximum size of a single item in DynamoDB is 400KB.
As for when to store document data, we decided first of all to persist the data to S3 every 30 seconds. We felt that this struck an appropriate balance between minimizing the amount of data that would be lost in the event of server failure, and reducing demand on the server. This is also in line with the 30- to 60-second “checkpointing” interval used by Figma .
We also persist document data to S3 when the last user leaves the room. When no more users are collaborating on a document, we don’t want the server to have to keep the document data in memory. Therefore, to free up these resources, the server sends the data to S3 and unloads it from memory.
Finally, when a user connects to the server to collaborate in a given room, and the server does not have data for that room in memory, the server needs to query S3 for that data and retrieve it, if it exists.
Now we have a way of establishing WebSocket connections between users and the server, and a way to persist document data so that users don’t lose work when a collaboration session ends. Our developers, however, don’t have any good way of seeing how many rooms are active or how many users are connected at any given time. The next step is to give developers visibility into these metrics.
To do this, we need to persist metadata about connections and rooms somewhere. A relational database is an appropriate choice since it will help ensure data integrity and enable flexible and efficient queries in this case since our data is structured. For that reason we chose a PostgreSQL database provisioned in Amazon Relational Database Service (RDS).
To access this room metadata, we added GET routes to the server. The dashboard sends HTTP requests to these routes, and the server responds with data such as the number rooms and connections per room that are used to populate the dashboard. For the number of connections for a given room, a continuous stream of data is sent from the server to the dashboard client via an SSE stream established via one of these GET routes.
We now have the basic components of the Symphony backend in place: a WebSocket server to exchange document updates with clients, an S3 bucket where document state is persisted, and a PostgreSQL database for storing metadata.
The next step is to enable a web application to connect to this backend. For this, a client library is needed to communicate with the server in accordance with the Yjs library’s protocols for syncing document updates and broadcasting awareness. Since one of the goals of our project is to make adding real-time collaboration functionality as easy and painless as possible for the developer, we gave this library an API that emphasizes simplicity and intuitiveness.
As was mentioned earlier, we want offline users to be able to continue working after disconnection and sync their changes later when they reconnect. This means that state needs to be stored locally, which also lies within the responsibility of the client library. In Symphony, user changes are written to IndexedDB in the browser before being sent to the server.
With the server deployed to EC2, the developer remains responsible for managing the server–applying security updates, handling logs, etc. We wanted Symphony to abstract away this backend management from the developer, in line with our design philosophy of making an easy-to-use framework.
With that in mind, we moved our architecture into AWS Elastic Container Service (ECS), a fully managed container orchestration service for deploying, managing, and scaling containerized applications.
To do this, we first had to containerize our application, and then reference that Docker container in an ECS task definition. The task definition is then referenced by a service definition which indicates how many instances of the container we want to run. ECS also gives you the choice of deploying in EC2 or Fargate mode. EC2 mode gives developers more granular control over container instances, at the cost of needing to manage instance configuration and updates. Since we wanted to abstract away this management from the developer, we chose Fargate.
Now that we have a Symphony client as well as a dashboard client for developers accessing our backend, we want a single point of entry for both. An Application Load Balancer (ALB) that sits in front of our backend gives us this single point of entry, and also routes traffic to individual instances of our WebSocket server in the scaled form of our architecture, which will be discussed in a later section.
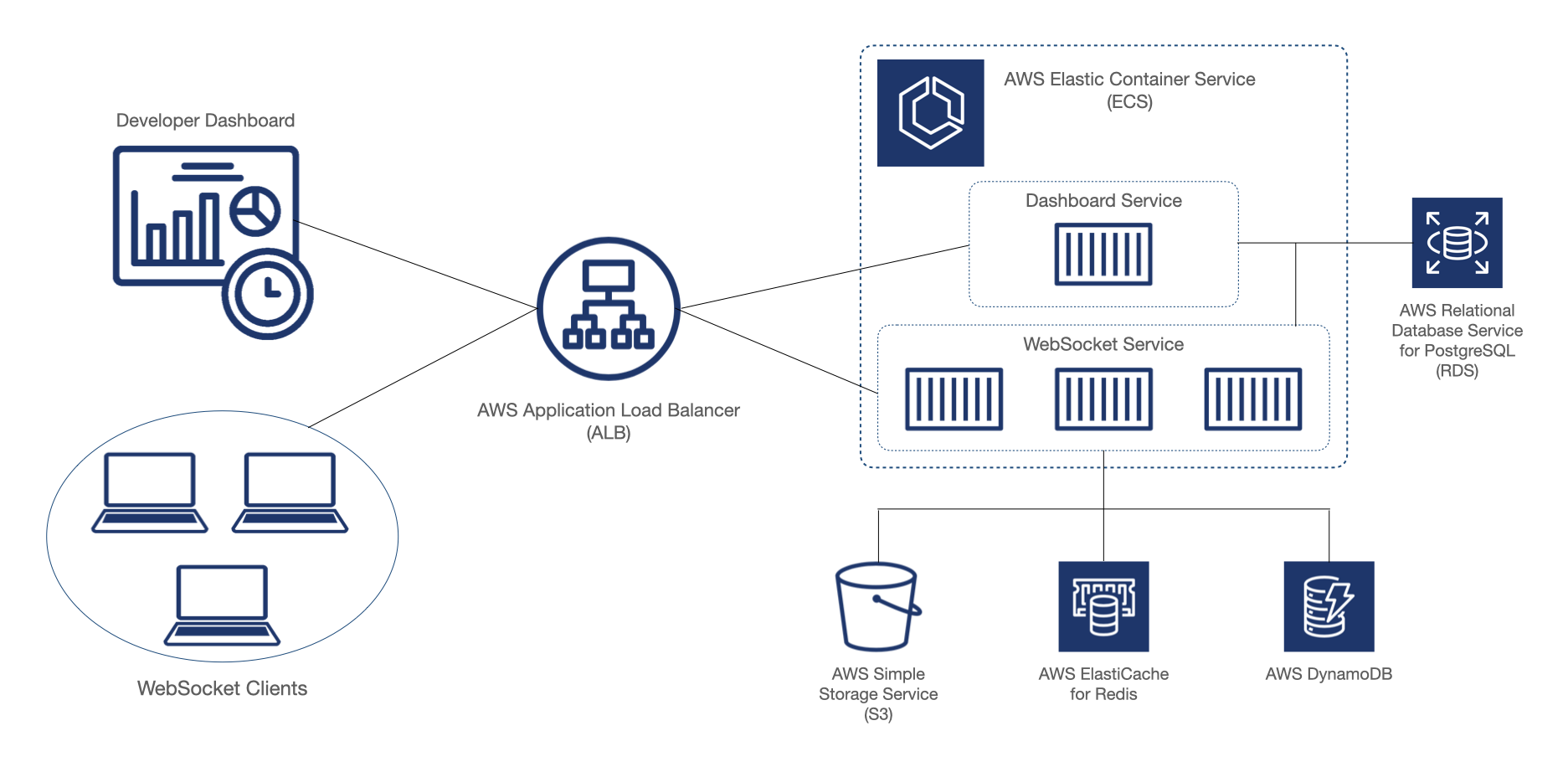
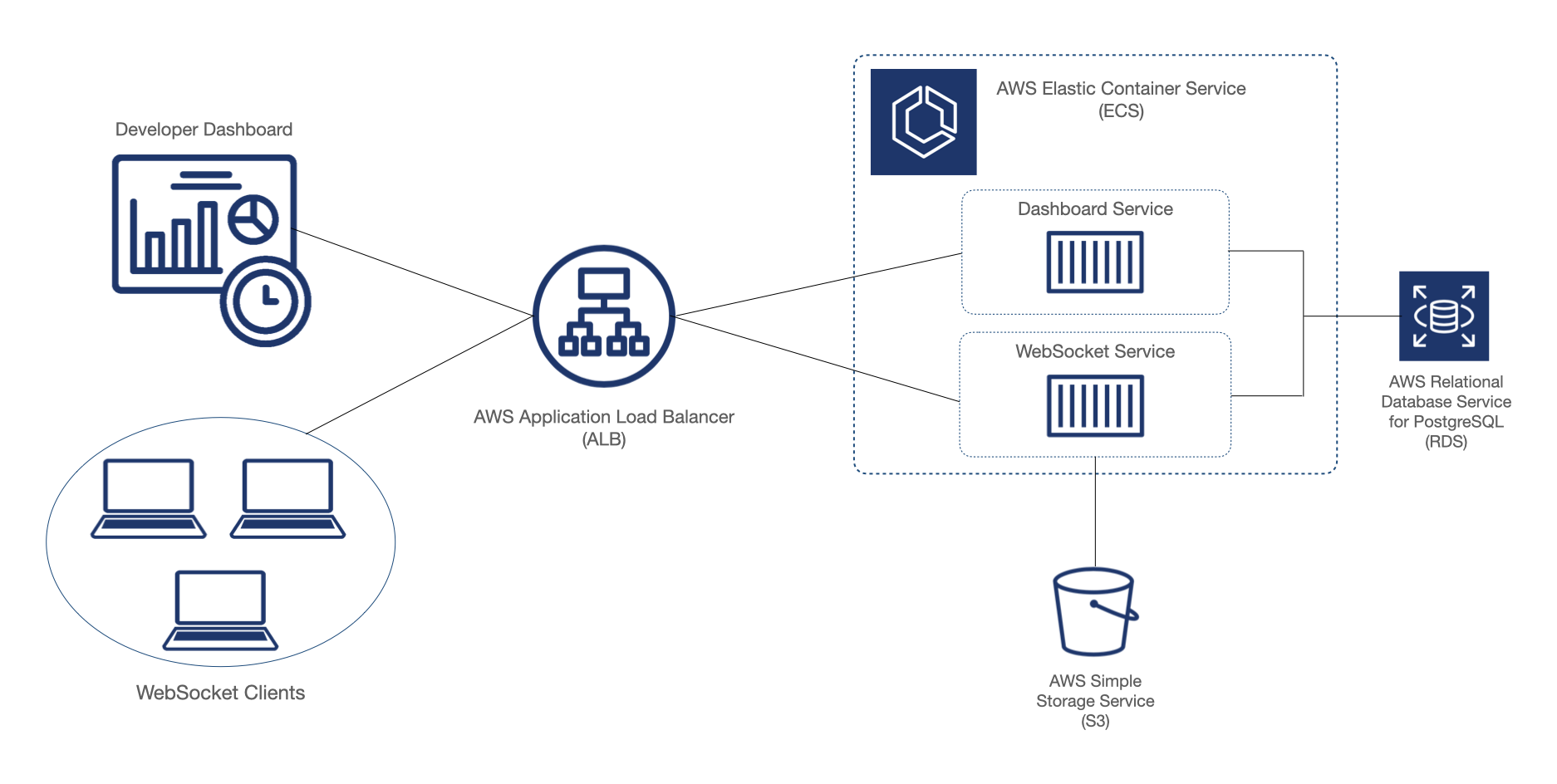
The diagram below shows our completed Symphony backend prototype with a single server instance running in ECS. Note that while ECS is a scalable service, our server isn’t actually scalable yet, for reasons we’ll discuss later.
Now that our prototype was up and running, we wanted to test how many users could connect to a single instance of the server at once, under as close to real-life conditions as possible. We also wanted to identify our server’s bottlenecks (especially compute vs memory) to inform our scaling strategy.
We first needed a way to establish a large number of user connections, with each virtual user sending document updates and broadcasting presence. To do this, we wrote a Node.js script to spawn a separate process for each user connecting to the backend. Since creating multiple users and handling updates for those users is very demanding in terms of CPU, we provisioned multiple EC2 instances to run the script and connect to the backend concurrently.
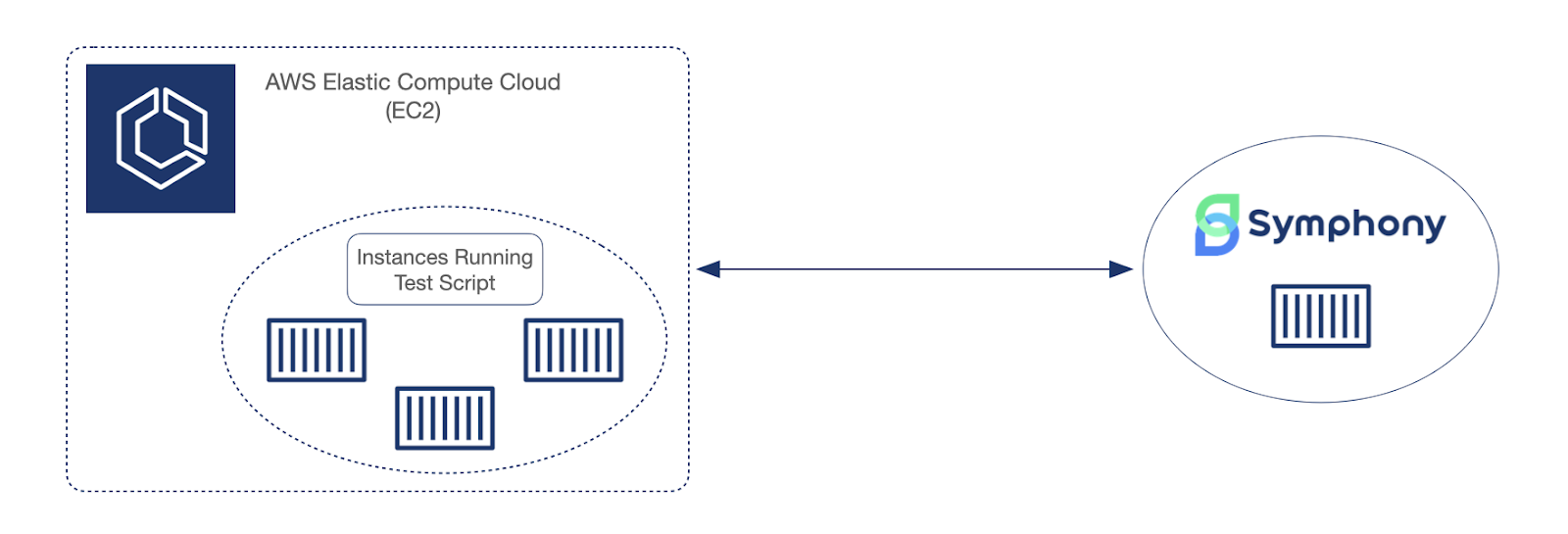
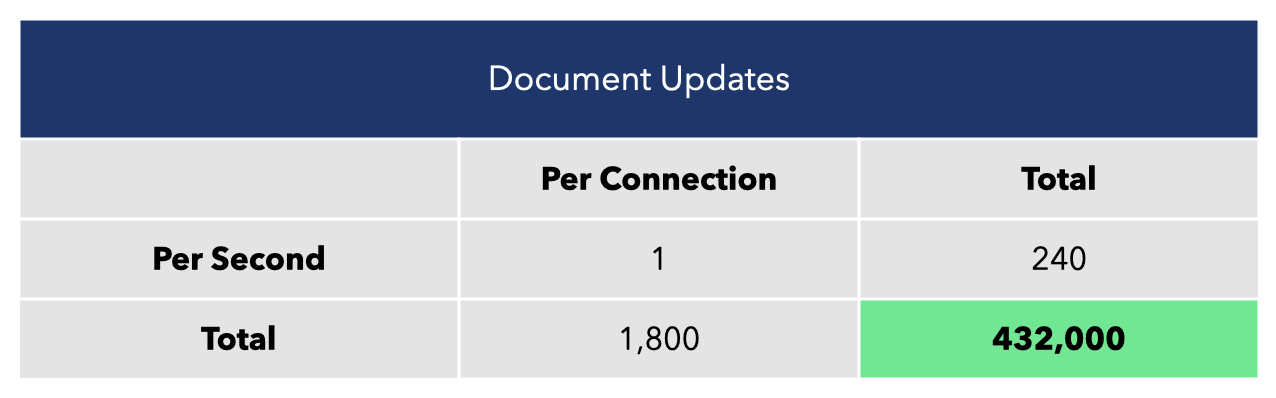
For the test itself, we provisioned a single WebSocket server with 1vCPU and 4GB of memory. We configured our script to create 240 users with 4 users per room, giving us a total of 60 rooms. The test was run for 30 minutes.

In our script, each virtual user transmits one document update per second.
Each virtual user also transmits five presence updates per second.
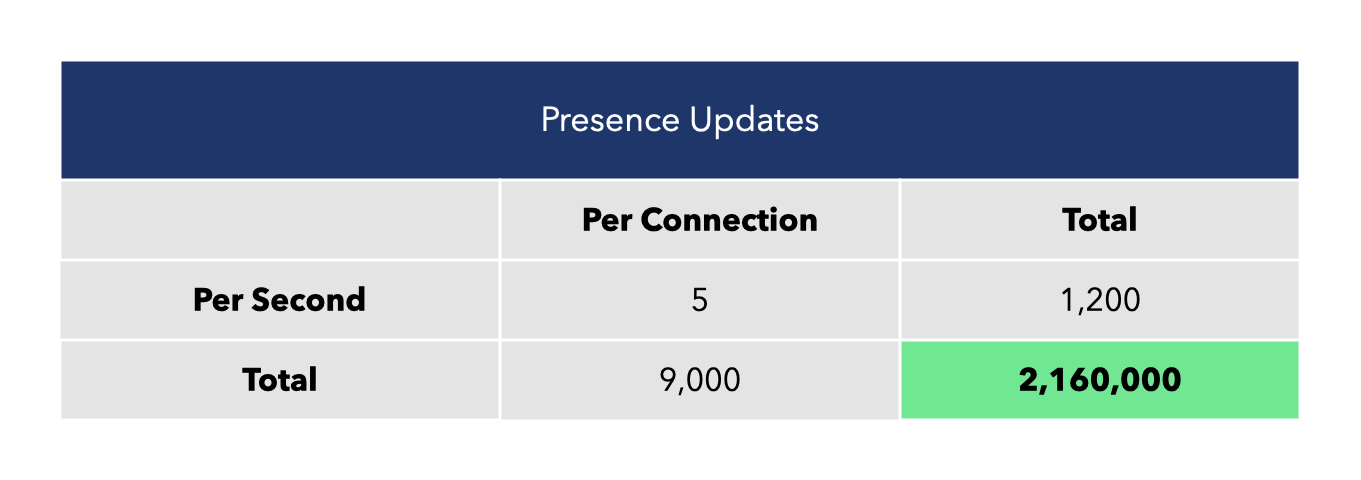
While the rates of document and presence updates could vary widely depending on the specific use case, we felt that these were reasonable values to simulate real-world usage (Liveblocks’ default settings throttle user updates to 10 per second, for comparison).
During the test, we observed CPU usage steadily climb as our virtual users connected to the backend. Once all connections were established, CPU usage had reached about 92%. This figure continued to slowly increase as the test went on, which we believe was due to the increased compute requirements as document sizes grew. After 30 minutes, CPU usage had reached 94% and we started to see dropped connections.
These results indicate that for a modestly provisioned server with 1vCPU and 4GB of memory, our system can handle about 240 concurrent users.
It would be possible to increase the number of users by vertically scaling–provisioning a server with greater compute and memory capacity–but scaling up our system in this way would have downsides. First, the WebSocket server would continue to have a single point of failure. If that server goes down, the system becomes unavailable. Second, scaling would be hard-capped by the maximum server size offered by AWS.
For these reasons we decided to explore horizontally scaling, which means increasing the number rather than the size of our servers. This would make our system capable of handling more users, while also being more resilient to server failures.
With load testing results in hand, we turned to the task of scaling out our architecture to accommodate a greater number of users.
But before we start thinking about how to actually scale our architecture, we’ve got a little housekeeping to take care of.
Our WebSocket server and dashboard server currently reside in the same code. We want to scale the WebSocket server so that our system can support more users, but we don’t need to scale the dashboard server. We therefore extracted the dashboard routes into a separate server, containerized it, and deployed a single instance of it to ECS.
With that out of the way …
AWS ECS Fargate offers auto scaling out of the box, based on metrics like average CPU and memory usage. So with our containerized WebSocket server currently deployed to Fargate, isn’t the Symphony backend already scalable?
Not quite. If we try to scale now, we’ll find that users who are in the same room but connected to different servers are out of sync.
Why is that?
The problem is that not all WebSocket servers will have the same documents loaded in memory. Imagine that users A and B want to join the same room for a collaboration session. User A joins first and is routed by the ALB to server #1; he begins making some document updates. A little while later, user B joins the same room and is routed to server #2. But user A has been sending updates to server #1. How can server #2 know the current state of the document?
This is not a problem unique to the Symphony backend. One common pattern for scaling WebSockets is to have each server connect to Redis channels: to a “publish” channel to send all updates received by the server from users, and to a “subscribe” channel to receive all updates published by other servers. In this way, we can scale our servers horizontally and they will be able to receive all updates they need for their connected users. Indeed, this is how existing attempts to scale Yjs backends with Redis, such as y-redis, have worked.
However, we’ve still got a problem.
When a server receives an incoming connection for a given room for the first time, it doesn’t just need to receive all future updates to that room’s state. It also needs to somehow get all previous updates to state. If we’re using the traditional Redis pub/sub approach, this means that every server needs to subscribe to Redis for every document, and needs to hold every document in memory, to ensure that the state is there when it needs it–when a user connects and starts collaborating on that state. In other words, we haven’t actually done anything to reduce the memory demands on our servers.
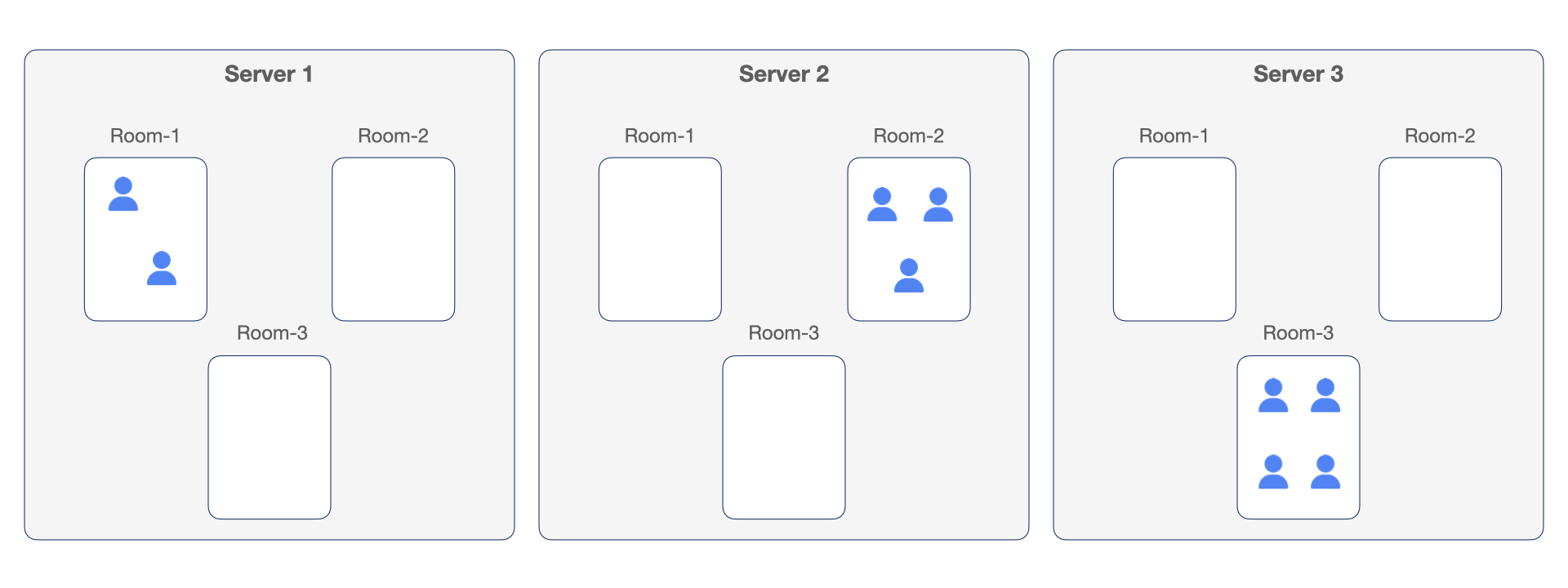
What if we could design the system in such a way that servers don’t need to hold all documents in memory–but instead, only the documents for which they have connected users? In that case, when a server receives a connection for a room for the first time, it would need to get the current document data from somewhere.
But from where?
One idea that came to mind was to allow servers to query each other for that initial state. In this way, a server receiving a new connection could get “up to speed” so to speak on the current state of the document, and then subscribe to Redis for all future updates.
If a server is going to get document data from another server, the next question is, how does it know which server to query? We would need to store data–room names and IP addresses–indicating which rooms are being handled by which servers.
For this we chose AWS DynamoDB, a serverless NoSQL key-value database. While it might seem tempting to use Redis for both the pub/sub messaging system and the IP address data store, we decided against it. By using DynamoDB we could separate those concerns, leading to a cleaner architecture and preventing a potential overloading of Redis with multiple responsibilities.
When a user is routed to a server that does not have the relevant document in memory, the server queries DynamoDB with the room name.
If DynamoDB returns an empty set, it means that there aren’t any servers currently handling that room. In this case, the server queries S3 to get persisted data for the room, if any, and then publishes/subscribes to Redis for updates to that room.
If DynamoDB returns a set containing one or more server IP addresses, the server sends a GET request to the first IP address in the set. The responding server sends the current state of the document, and the requesting server then publishes/subscribes to Redis as usual. Note that in this case, our requesting server does not query S3 for persisted data. This is because another server is currently handling the room, meaning that S3 will not have the most recent state.
In either case, the server’s IP address is added to the DynamoDB set for that room name, registering it as one of the servers that can now be queried for the room’s state.
Our system is now capable of functioning with multiple WebSocket server instances deployed, but we don’t yet have any way of automatically increasing or decreasing the number of instances in our ECS cluster.
In ECS, this can be accomplished using target tracking scaling, in which you set a target value for a metric such as CPU utilization, and AWS automatically adjusts the number of tasks running in your cluster to maintain that target. Since our single-server load test had identified CPU utilization as the bottleneck, we set a target tracking scaling policy to target 50 percent CPU utilization for our cluster. Our system will now scale out when CPU usage exceeds that number, and scale in when it is lower than that number.
There’s one last bit of cleanup that we need to take care of. What happens when the last user for a room disconnects from a server, and the server unloads the relevant document from memory? We don’t want other servers to query it for that state, because it doesn’t have that state any longer.
To handle this, after the last user connected to a server for a given room disconnects, but before the server backs up the document data to S3 and unloads that data from memory, the server sends a query to DynamoDB to remove its IP address from the set for the relevant room.
Our final architecture is below:
With our scaled solution in place, we set out to test if it could support the 8,000 concurrent users we had been aiming for.
For consistency and comparability, we used the same parameters as when we tested the single-server prototype: four virtual users per room, five presence updates per user per second, and one document update per user per second. Each server within the ECS cluster was provisioned with 1vCPU and 4GB of memory, matching the specifications used during single-server testing.
First, we ran a test with 1,000 virtual users. We observed the number of WebSocket instances scaling out as expected, and the system appeared capable of handling this number of users. As soon as we tried to push the number of users a little higher to 1,200, however, instances started to fail.
The culprit turned out to be the routing algorithm used by our ALB. By default, the ALB uses a round-robin algorithm in which requests are routed to each instance in turn without any consideration for how much each instance is being utilized. In our case, that meant that even if one instance had 90% CPU utilization and another had 10%, both instances were receiving an equal number of new connections, causing the first instance to eventually fail.
The solution was to configure the ALB to use a least-outstanding-requests algorithm, which routes incoming requests to the instance with the least number of outstanding requests, taking the load off overloaded servers.
We ran our test again with 1,200 virtual users, and saw no issues this time. We then continued adding users and at 10,000 virtual users, CPU utilization for the cluster remained near the 50 percent target, without any server failures observed.
While our final architecture exceeded our initial goal of supporting 8,000 concurrent users, we’ve started to think about how we might be able to do even better.
Our final architecture allows our WebSocket servers to scale horizontally, but we still see some duplication of rooms across servers. This inefficiency means that developers are provisioning more resources than are strictly needed to handle their WebSocket traffic, and these resources come at a cost.
One design pattern we’ve noticed in the real-time collaborative space is what we’ll call the “single room per container” design. In this approach, each instance of the WebSocket server is responsible for only a single room, and all users for a given room are routed to the same server. Figma, a collaborative web application for interface that uses a custom-built WebSocket backend and conflict resolution mechanism, appears to use this pattern.
"Our servers currently spin up a separate process for each multiplayer document which everyone editing that document connects to." - Evan Wallace, Figma
A possible advantage of this approach might be improved CPU and memory efficiency. If all traffic for a given room is routed to the same container, there will be no duplication of room states across servers.

South Carolina, US

London, UK

Michigan, US
London, UK
